


Your contact center is sitting on a goldmine of customer insight. Are you using it?
Discover how to unlock hidden insights from customer conversations to improve CX, reduce churn, strengthen agent performance, and drive better decisio...
Share
If you have spent any time looking at our platform, you have come across the concept of a category. In AI research, we focus a lot of energy on this fundamental building block and thought taking a moment to talk about what a category is and how we are researching it is important.
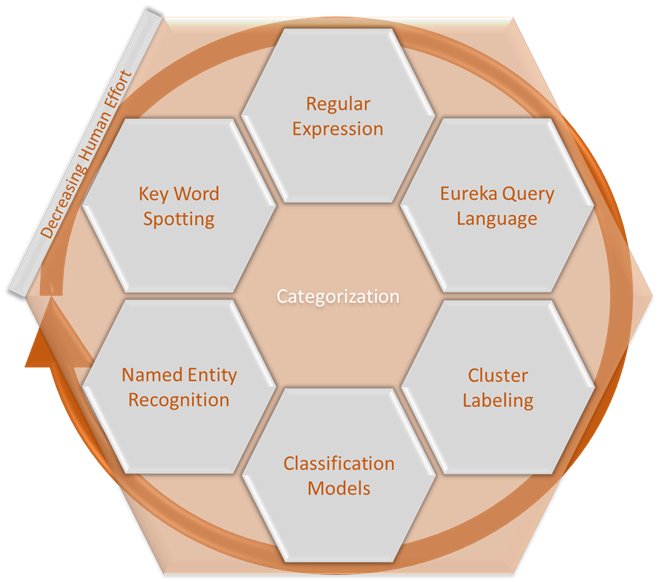
Let’s explore categorization a bit by looking at several different ways a human or machine can categorize element of conversations.
At its most basic, the ability to search a transcript for a relevant word is useful. Knowing a specific word is in a transcript allows for a basic categorization of the document. If the word can be spotted in its location, then an area of an interaction can be also categorized.
The issue with key word spotting is the imprecision. It is a blunt tool. It takes a lot of effort to figure out if the word is used in a relevant way to the desired categorization. Key word spotting is basic, and useful, but not effective at scale.
Regex is a better way to find relevant portions of a transcript to categorize. Regex is a programming language that allows a user to find a sequence of characters that form a pattern. Patterns such as the letters spaces that form words, regex allows a user to define patterns and look for them, like a phrase or a sentence.
Because regex is a programming language, it has operators that allow for multiple options to be found, which is far more effective than word spotting. In regex a user can find things like:
Dog|cat (dog or cat)
De(a|e)r (deer or dear)
And other handy things like wild cards where you can find all the variants of a word. Or {n}, {min,} and {,max} where a preceding item can be matched a minimum, maximum or specific number of times. Handy regex can only go so far because it is very labor intensive to build large regex patterns. They must be tested and refined constantly as the documents evolve.
That is not to say it is not powerful, it is very effective after the intense effort is complete.
EQL is our proprietary method to find and categorize any and every part of an interaction from broad to incredibly specific. EQL starts with souped up pattern recognition, a simple user-friendly approach and adds in many more elements. A query can consist of any meta data in the system, either interaction specific or general data. A plethora of measures of any interaction, and even other EQL. They can be stacked, like building blocks on each other.
Once built, it can easily be tested and refined, then set to automatically run each time a new interaction is ingested in the system. You can even reach back over older interaction with EQL.
EQL is elegant, friendly and above all, highly accurate.
There is a limitation to each of these methods, at their core they are based on word sequences. Even EQL requires a user to know what they are looking for.
Based on a combination of machine advantages and disadvantages they attack categorization in a very different way. Many different ways in fact. A machine has the advantage of consuming enormous amounts of data tirelessly. But a machine, no matter how rich in artificial intelligence (AI), is lacking some level of context. We humans must take time to give it that, as best we can.
Clustering is a primary machine learning (ML) tool we use to structure unstructured data such as conversations. This approach is able to find the context of a word or phrase based on its use in conversation. Essentially it can find the context of a word in a client’s data, how they specifically use it. Clusters are the basis for contextual search in our product called Illuminate.
Labeling the concepts represented by each cluster helps simplify the variations in how things are said. When we replace specific words with the concepts they represent, the variations in the way we say things start to minimize. As we all know, there are many ways to say the same thing, a machine will cluster them all together. A transcript of words becomes a sequential map of concepts. As reoccurring patterns start to emerge, our blueprint expands beyond the basics. We link these blueprints to specific events. Consider a few ways someone expresses that a website is down. Now we can know the issue regardless of how a person expresses it.
If a cluster can identify all the ways something is said, a model can predict with a degree of probability that it was said. We are building models to identify if important things are said in calls. Like why people call our client’s, what we term a “Call Driver”.
Currently, we are specifically focusing on the location of the call driver in a call, where it was said, and exposing that. While call reasons can vary depend on the industry that the call center is related to, our models can identify the location regardless.
For example, a healthcare billing call center will have different call drivers than an exercise equipment call center. We can identify the location of both because the way a customer is stating the reason for call in the context is similar.
Named Entity Recognition (NER) is a task that aims to find a given class of nouns (traditionally People, Organizations, and Geopolitical Entities) in text. Our model uses state-of-the-art ML to recognize the similarities both in word (like very much like Illuminate does) and in context to find new instances of the given word class, and can be trained for pretty much any class of nouns (like drug names, company name, etc.). Unlike our traditional categories, which rely on a consistent pattern of words, our ML-based model can identify the same context in a much broader set of contexts. NER goes well beyond regex patterns in ways word patterns can’t handle. Even more intriguing, these algorithms learn as they are exposed to new data.
Categorization is one branch of research that continues to be highly important to analyzing conversations. The ability to find, count, sort, score and classify elements of a conversation are paramount to understanding complex human interactions.
The use of advanced AI to categorize such data is imperative. There are many more methods that those I mention which we are researching at to categorize conversational elements. The three AI approaches above are areas that will be the future of conversation analytics platforms such as CallMiner.




